Training a Classifier
1 | import torch |
1 | import torch |
1 | transform = transforms.Compose( |
1 | transform = transforms.Compose( |
這段程式主要的目的,是建立一個可以讓 PyTorch 模型方便使用的影像資料載入流程。首先,程式定義了一個名為 transform 的轉換流程,這個轉換由兩個步驟組成。第一個步驟 transforms.ToTensor() 是把原本的影像(可能是 PIL Image 或 numpy 陣列)轉成 PyTorch 可以處理的 Tensor 格式,並且把像素值從 0~255 縮放到 0~1 之間。第二個步驟 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) 則是將每個顏色通道進行標準化,把影像的數值範圍轉換成 -1 到 1 之間,這樣能讓模型在訓練時更穩定、更容易收斂。
接著,batch_size = 4 表示每次從資料集中取出四張圖片,組成一個小批次(batch)來訓練。這樣做可以減少記憶體使用量,並加快訓練速度。
在建立訓練資料集時,使用了 torchvision.datasets.CIFAR10 這個內建的資料集。CIFAR-10 是一個常見的影像分類資料集,裡面有 10 種不同類別的物體(例如飛機、汽車、貓、狗等)。參數 root='./data' 代表資料會被存放在專案資料夾中的 data 目錄下;train=True 指定要載入訓練資料;download=True 讓程式在本地沒有資料時自動從網路下載;而 transform=transform 則確保每張影像在載入時都會先經過剛剛定義的轉換流程。
建立好訓練資料集後,trainloader 透過 torch.utils.data.DataLoader 將資料集包裝成可以分批次讀取的形式。這個物件會在訓練時自動提供圖片與標籤。shuffle=True 表示在每個訓練輪次(epoch)開始前,資料都會被隨機打亂,避免模型記住資料的順序而影響學習。num_workers=2 則是設定使用兩個背景執行緒加快資料載入的速度。
測試資料的部分幾乎相同,只是 train=False 代表這次載入的是測試資料集,並且 shuffle=False,確保測試資料的順序固定,方便在評估模型時對照結果。
最後,classes 定義了一個包含 10 個字串的元組,對應到 CIFAR-10 資料集的十個分類名稱,分別是飛機(plane)、汽車(car)、鳥(bird)、貓(cat)、鹿(deer)、狗(dog)、青蛙(frog)、馬(horse)、船(ship)以及卡車(truck)。
1 | import matplotlib.pyplot as plt |
1 | import matplotlib.pyplot as plt |
這段程式的主要功能是從訓練資料集中隨機取出一批圖片,將它們組合起來顯示在螢幕上,並同時印出每張圖片所對應的分類名稱。它常用於訓練前的資料檢查,讓我們確認影像資料是否被正確載入與轉換。
首先,程式匯入了 matplotlib.pyplot 和 numpy,前者用來繪製和顯示圖片,後者則是進行陣列處理。接著定義了一個名為 imshow 的函式,用來顯示影像。由於在資料載入時影像經過標準化(值從 [0,1] 變成 [-1,1]),因此在顯示之前需要進行反標準化,也就是 img = img / 2 + 0.5 這一行,把影像還原到可視範圍 [0,1]。接著 npimg = img.numpy() 將 PyTorch 的 Tensor 轉成 NumPy 陣列,因為 Matplotlib 只能處理 NumPy 格式的資料。再來,np.transpose(npimg, (1, 2, 0)) 這行是把影像的維度順序從 (channels, height, width) 調整成 Matplotlib 所需要的 (height, width, channels)。最後透過 plt.imshow() 顯示圖片,plt.show() 則把圖形真正畫出來。
在顯示影像之前,程式會先從訓練資料中取出一批圖片。這裡 dataiter = iter(trainloader) 建立一個可迭代物件,用來從資料載入器中取得資料,而 images, labels = next(dataiter) 則是取出下一批資料。這一批資料包含了四張圖片(因為之前設定 batch_size = 4),以及這四張圖片的標籤。

接著使用 torchvision.utils.make_grid(images) 將多張圖片排成一張網格,方便一次顯示多張影像。這個網格會被傳入 imshow() 函式中顯示出來。最後一行 print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size))) 則是依序把每張圖片的類別名稱印出來。它會根據 labels 取得每張圖片的類別代號,再利用 classes 對應到實際的名稱(例如 “cat”、”dog”、”car” 等),並用空格分隔後印在同一行。
1 | import torch.nn as nn |
1 | import torch.nn as nn |
這段程式定義並建立了一個基本的卷積神經網路(Convolutional Neural Network, CNN),用來進行影像分類。這個網路的結構與 LeNet 類似,是一個簡單但經典的 CNN 範例,常用於 CIFAR-10 這類小型影像資料集的學習實驗。
首先,程式匯入了 torch.nn 與 torch.nn.functional。前者提供各種神經網路層的模組,例如卷積層、線性層(全連接層)等;後者則提供常用的函式操作,例如激活函式 ReLU(Rectified Linear Unit)等。
接著,透過定義一個名為 Net 的類別來建立網路結構。這個類別繼承自 nn.Module,是 PyTorch 中所有模型的基底類別。__init__ 方法中定義了網路的各個層。self.conv1 = nn.Conv2d(3, 6, 5) 是第一個卷積層,它的輸入有三個通道(對應到彩色影像的 R、G、B 三色),輸出六個特徵圖(feature maps),而卷積核(filter)的大小是 5×5。接著 self.pool = nn.MaxPool2d(2, 2) 是最大池化層,用於縮小影像尺寸,減少參數與計算量。self.conv2 = nn.Conv2d(6, 16, 5) 是第二個卷積層,輸入為六個通道、輸出十六個特徵圖,同樣使用 5×5 的卷積核。
卷積層之後是三個全連接層(fully connected layers),也就是傳統神經網路的部分。self.fc1 = nn.Linear(16 * 5 * 5, 120) 代表第一個全連接層的輸入為 16×5×5 維的向量(也就是前面卷積與池化之後展平的結果),輸出為 120 個神經元。接著的 self.fc2 = nn.Linear(120, 84) 再將輸入從 120 維轉成 84 維,而最後一層 self.fc3 = nn.Linear(84, 10) 則輸出 10 維的結果,對應到 CIFAR-10 的十個分類類別。
在 forward 方法中定義了資料的前向傳遞過程,也就是影像如何一步步通過網路。首先,輸入 x 經過第一個卷積層 self.conv1,然後經過 ReLU 激活函式轉換,再經過最大池化層縮小尺寸。接著進入第二個卷積層 self.conv2,同樣再經過 ReLU 與池化層。這兩次卷積與池化之後,影像的空間維度大幅縮小,但特徵變得更抽象、更具辨識能力。接下來使用 torch.flatten(x, 1) 將多維的特徵圖展平成一維向量(除了批次維度外),使其能夠輸入到全連接層。然後依序通過兩層帶有 ReLU 激活函式的全連接層,最後輸出到 fc3,產生最終的分類結果。
最後一行 net = Net() 則是實際建立這個網路的實例。建立後的 net 物件就是一個可供訓練的 CNN 模型,能夠接收 CIFAR-10 的影像作為輸入,並輸出十個類別的預測結果。整體而言,這段程式展示了從卷積層、池化層到全連接層的完整 CNN 結構,構成了一個典型的影像分類模型。
補充 : ReLU 的作用

它會把所有負值剪掉,正值保留。
1 | import torch.optim as optim |
1 | import torch.optim as optim |
這段程式的主要功能,是為神經網路設定損失函數(loss function)與優化器(optimizer),也就是訓練模型時用來「評估表現」與「更新權重」的兩個關鍵步驟。它們就像訓練過程中的「老師」和「調整機制」,共同決定模型如何從錯誤中學習。
首先,criterion = nn.CrossEntropyLoss() 這行定義了損失函數,使用的是交叉熵損失(Cross Entropy Loss)。交叉熵是一種在分類問題中最常見的損失函數,它用來衡量模型預測的機率分佈與真實答案之間的差距。舉例來說,若模型預測一張圖片是「貓」的機率為 0.9,而真實標籤確實是貓,那損失值就會很小;但如果模型預測是「狗」的機率為 0.9,損失值就會很大。這樣模型在訓練時會自動調整權重,讓正確類別的機率越來越高。CrossEntropyLoss 在 PyTorch 中同時結合了 softmax(將輸出轉為機率)與 log loss(計算對數誤差),因此不需要手動再對輸出做 softmax 處理。
接著,optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) 這行設定了優化器,使用的是隨機梯度下降法(Stochastic Gradient Descent, SGD)。在訓練神經網路時,模型會根據損失函數的值計算出梯度,表示權重應該如何調整以降低損失。SGD 就是透過這些梯度逐步更新模型的參數。net.parameters() 表示要讓優化器管理網路中所有可學習的權重;lr=0.001 則是設定學習率(learning rate),也就是每次更新權重時的步伐大小。學習率太大會導致訓練不穩定、損失值震盪;太小則會讓收斂速度變慢。最後的 momentum=0.9 是動量參數,它能幫助模型在訓練過程中更順利地前進,減少在局部最小值附近震盪的情況。動量的概念就像 推球一樣,當球在斜坡上滾動時,會保留部分前一次的速度,讓更新方向更平滑、加速收斂。
總結來說,這段程式的作用是建立訓練模型時的「學習機制」:交叉熵損失負責告訴網路「預測錯了多少」,而 SGD 優化器則根據這些錯誤去微調權重,讓模型一步步學會更準確地分類影像。
Train the network
1 | for epoch in range(2): # loop over the dataset multiple times |
1 | for epoch in range(2): # loop over the dataset multiple times |
這段程式是整個模型訓練過程的核心,它讓神經網路能夠不斷從資料中學習、修正錯誤,進而提升分類準確率。最外層的 for epoch in range(2): 代表訓練要進行兩個回合(epoch),也就是讓模型將整個訓練資料集完整學習兩次。每個 epoch 開始前,先將 running_loss 設為 0,這個變數用來累積損失值,以便在訓練過程中觀察模型表現是否逐步改善。
在每個 epoch 內部,for i, data in enumerate(trainloader, 0): 會從訓練資料載入器(trainloader)中依序取出資料批次(mini-batch)。每次取出的 data 由兩個部分組成:inputs 是輸入影像的張量(tensor),而 labels 是對應的真實分類標籤。由於前面設定過 batch_size = 4,因此每個批次會包含四張圖片與它們的標籤。
接著,optimizer.zero_grad() 是一個非常重要的步驟,用來清除前一次訓練所累積的梯度(gradient)。在 PyTorch 中,梯度會自動累加,若不清零,前一批的梯度會干擾新的更新,使模型權重被錯誤地調整。清除梯度之後,就能安全地開始新的學習迭代。
在這之後是整個學習流程的三個主要階段:前向傳播(forward)、反向傳播(backward)與參數更新(optimize)。outputs = net(inputs) 代表把輸入圖片送進神經網路中進行前向運算,網路會輸出一組預測結果。接著,loss = criterion(outputs, labels) 使用損失函數計算預測值與真實標籤之間的差距,損失值越大代表模型預測越不準確。loss.backward() 則是反向傳播的步驟,PyTorch 會根據損失值自動計算每個參數的梯度,也就是「模型應該怎麼修正自己」。最後,optimizer.step() 根據這些梯度更新模型的權重,使得網路在下一次預測時能更接近正確答案。
在每次迭代結束後,running_loss += loss.item() 會把這一批的損失值加總起來。為了方便觀察訓練進展,程式設計成每訓練 2000 批資料時,就會印出一次平均損失值:print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')。這樣可以直觀看出損失值是否持續下降,進而判斷模型是否正在有效地學習。印出後,running_loss 會被重置為 0,準備記錄下一段訓練的結果。
當外層的迴圈結束後,代表模型已經完成所有訓練回合,print('Finished Training') 會顯示訓練完成的訊息。
1 | PATH = './cifar_net.pth' |
1 | PATH = './cifar_net.pth' |
首先,PATH = './cifar_net.pth' 是設定模型要儲存的路徑與檔案名稱。這裡使用的 './cifar_net.pth' 代表在目前的工作目錄下建立一個名為 cifar_net.pth 的檔案。副檔名 .pth 是 PyTorch 模型檔案的常見命名方式,代表「parameters of torch」(意即儲存的是模型的參數)。
接下來的 torch.save(net.state_dict(), PATH) 是實際執行儲存的動作。這裡的 net 是前面訓練完成的神經網路,而 net.state_dict() 是一個特殊的字典(dictionary),裡面儲存了模型中所有層的參數權重(weights)與偏差值(biases)。換句話說,它只會保存模型「學到的知識」,而不是整個模型結構。這樣的設計讓儲存檔案更小、更靈活,也方便在不同環境中重新載入。
1 | dataiter = iter(testloader) |
1 | dataiter = iter(testloader) |
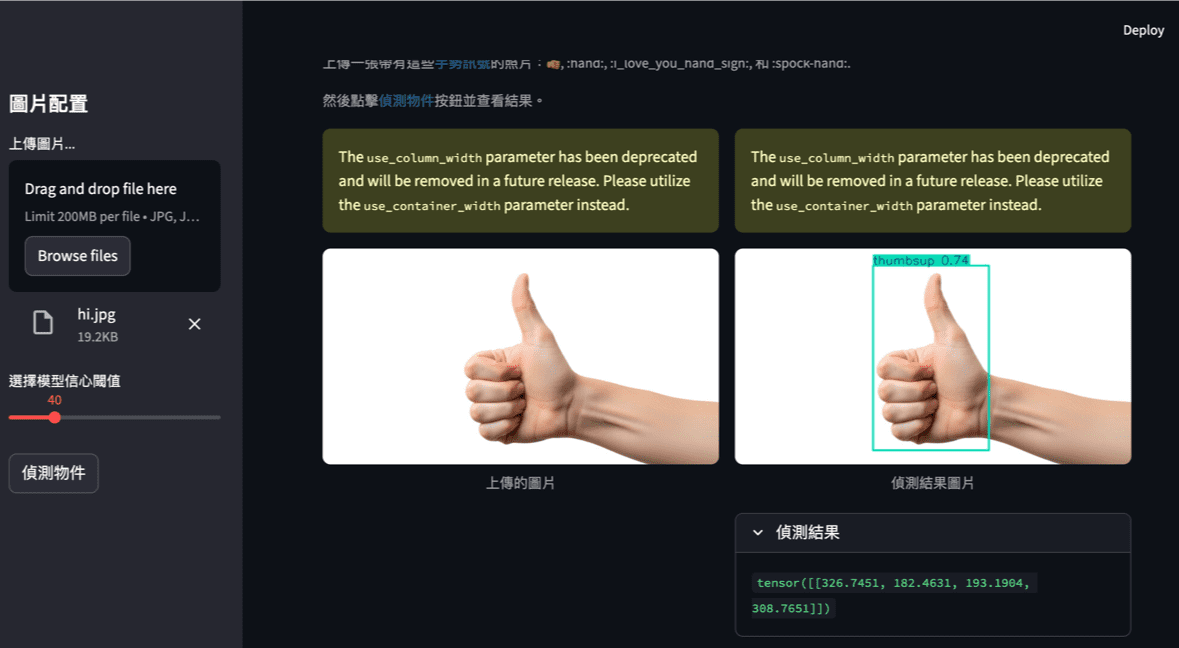
這段程式的功能是從測試資料集中隨機取出幾張圖片,顯示出它們的內容,並印出每張圖片的真實標籤(Ground Truth)。這通常是訓練完成後的第一個步驟,用來檢查測試資料是否正確載入,也方便之後與模型的預測結果進行比較。
首先,dataiter = iter(testloader) 用來建立一個可迭代的資料讀取器。testloader 是先前設定好的測試資料載入器,裡面包含了 CIFAR-10 的測試圖片與對應標籤。接著,images, labels = next(dataiter) 從這個載入器中取出一批資料。這一批包含兩部分:images 是四張測試圖片的影像張量(tensor),labels 則是這四張圖片的真實類別標籤,以數字形式儲存。例如,若某張圖片的標籤是 3,就代表它屬於 CIFAR-10 類別中的「cat」。
接下來的 imshow(torchvision.utils.make_grid(images)) 是用來顯示圖片。由於這次取出的 images 是四張影像,因此使用 torchvision.utils.make_grid(images) 先把這四張圖排成一張大圖(grid),再交給 imshow() 函式顯示出來。imshow() 會先將影像資料反正規化(把像素值從 -11 的範圍還原為 01),然後利用 Matplotlib 將這張圖片網格畫出來。執行這行後,畫面上會出現四張並排的小圖片,也就是接下來模型要進行預測的測試樣本。

最後一行 print('GroundTruth: ', ' '.join(f'{classes[labels[j]]:5s}' for j in range(4))) 則負責印出這四張圖片的真實類別名稱。這裡的 classes 是先前定義好的 CIFAR-10 類別名稱列表,例如 ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')。labels[j] 會取出每張圖片的數字標籤,而 classes[labels[j]] 則將這些數字轉換為對應的文字名稱。' '.join(...) 用來把所有類別名稱以空格串起來,讓輸出更整齊。
1 | net = Net() |
1 | net = Net() |
這段程式的主要功能是重新載入先前訓練並儲存好的模型權重,讓模型能夠直接使用訓練成果,而不必重新訓練。它通常出現在「模型測試」或「實際應用」的階段。
首先,net = Net() 這行代表建立一個新的模型物件。這個 Net 是先前定義好的神經網路結構類別(包含卷積層、池化層、全連接層等)。這裡建立的 net 是一個「空白的模型骨架」,也就是只有網路的架構,尚未包含任何已學到的參數或權重。
接下來的 net.load_state_dict(torch.load(PATH, weights_only=True)) 是將儲存在檔案中的權重載入到這個模型中。前面的 torch.load(PATH, weights_only=True) 是從先前儲存的檔案(例如 './cifar_net.pth')中讀取模型參數。這個檔案是在訓練結束後用 torch.save(net.state_dict(), PATH) 儲存的,因此裡面包含了每一層神經網路的權重(weights)與偏差(biases)數值。
load_state_dict() 則是 PyTorch 專門用來把這些儲存的參數載回模型的函式。當這個函式被呼叫時,它會根據模型層的名稱,自動將檔案中的權重一一對應回模型中相同名稱的層,讓這個新的 net 恢復成與訓練完成時相同的狀態。參數 weights_only=True 則指定只讀取權重數據,而不載入其他不必要的資訊(例如訓練時的設定或暫存變數),這樣可以確保載入過程簡潔且不受版本影響。
1 | outputs = net(images) |
1 | outputs = net(images) |
images 是一批(batch)要測試的影像資料,通常是從 testloader 中取出來的四張圖片(因為你先前設定 batch_size = 4)。這些影像已經是經過 transforms.ToTensor() 和 transforms.Normalize() 處理的張量(tensor),形狀通常是 (4, 3, 32, 32),分別代表:4 張圖片、3 個顏色通道(RGB)、以及 32×32 的解析度。
net 是你的神經網路模型物件(由 Net() 建立,並載入了已訓練的權重)。當你把 images 傳進 net() 時,PyTorch 會自動呼叫 Net 類別裡定義的 forward() 函式。也就是說,這行程式會讓圖片依序通過:
卷積層(Conv2d) → 萃取影像特徵;
ReLU 激活函式 → 引入非線性;
池化層(MaxPool2d) → 縮小影像尺寸;
全連接層(Linear) → 將特徵轉換成分類分數。
這些層會依照你在 forward() 方法中定義的流程一層層運算,最終輸出模型對每張圖片的分類結果。
1 | _, predicted = torch.max(outputs, 1) |
1 | _, predicted = torch.max(outputs, 1) |
這裡使用了 PyTorch 的 torch.max() 函式,它的功能是找出張量(tensor)中每一列的最大值以及它所在的位置。outputs 是模型對四張圖片的預測結果,形狀是 (4, 10),其中:
4 代表輸入的圖片數量;
10 代表 CIFAR-10 的十個分類(例如飛機、汽車、貓、狗等)。
對於每張圖片(每一列),模型會輸出 10 個數值,這些數值代表「模型認為該圖片屬於每個類別的信心分數」。torch.max(outputs, 1) 的第二個參數 1 表示沿著「第 1 維」進行操作,也就是在每一列(每張圖片的 10 個分數)中尋找最大值。

這個函式會回傳兩個結果:
最大值本身(這裡用
_省略掉,因為我們只關心位置而不需要數值);最大值的索引位置,也就是每張圖片信心分數最高的類別代號。
1 | correct = 0 |
1 | correct = 0 |
correct 用來計算預測正確的圖片數量,total 則用來計算測試資料的總張數。最終會用這兩個數字來計算正確率。
接著的 with torch.no_grad(): 是 PyTorch 中常見的寫法,表示在這個區塊中不需要追蹤梯度(gradients)。在測試或推論階段,我們並不需要做反向傳播(backpropagation)或更新權重,因此可以關閉梯度計算來節省記憶體與運算時間。這樣能讓模型運行得更快,也避免誤修改權重。
在程式中,for data in testloader: 會從測試資料載入器 testloader 中依序取出資料。每次取出的 data 代表一個批次(batch),其中包含四張測試圖片(images)及它們的真實標籤(labels)。接著,執行 outputs = net(images),讓模型對這些圖片進行前向傳播(forward pass),輸出每張圖片對應十個類別的分數(logits)。這些分數代表模型對每個類別的信心程度,分數越高表示模型越傾向認為圖片屬於該類別。
之後的這行 _, predicted = torch.max(outputs, 1) 用來從模型的輸出中,取出每張圖片分數最高的那一個類別,作為模型的預測結果。這裡的 predicted 是一個包含四個數字的張量(tensor),每個數字代表模型認為圖片所屬的類別索引(例如 0 代表「plane」、1 代表「car」等)。換句話說,這一步是將模型的「信心分數」轉換成實際的「分類決策」。
接著兩行 total += labels.size(0) 和 correct += (predicted == labels).sum().item() 是用來統計模型的預測表現。labels.size(0) 代表這一批圖片的數量(通常是 4),會加到 total 中,以累計測試圖片的總數。而 (predicted == labels) 會比較模型預測的類別與真實標籤是否一致,產生一個布林值陣列(例如 [True, False, True, True])。使用 .sum() 會將其中的 True 視為 1、False 視為 0,相加後就能得到這一批中模型預測正確的圖片數。最後,.item() 會把這個張量轉換成普通的整數,再加到 correct 裡,表示目前累積的正確預測數量。
當迴圈跑完所有測試資料後,模型就已經對整個測試集(共 10,000 張圖片)完成預測。

代表模型在 10,000 張測試圖片中,有 53% 被正確分類。

這裡的 100 * correct // total 使用整數除法,讓結果以百分比的形式輸出。
Training on GPU
1 | device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') |
1 | device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') |
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') 利用了 PyTorch 的 torch.cuda.is_available() 函式來檢查系統中是否安裝並啟用了 CUDA。若電腦中有支援的 NVIDIA 顯示卡且 CUDA 可用,這個函式會回傳 True,程式便會選擇 'cuda:0' 作為運算裝置,代表使用第 0 張 GPU(即第一張 GPU 卡)進行運算。若 CUDA 不可用,則回傳 False,程式會改用 'cpu',也就是中央處理器進行運算。torch.device() 則會依據這個結果建立一個「裝置物件(device object)」,方便之後將模型或資料移動到指定的裝置上執行。
接著這行 print(device) 會印出目前使用的運算裝置。如果系統有支援 CUDA 且 PyTorch 安裝的是 GPU 版本,輸出結果會是 cuda:0,表示模型將在 GPU 上執行;若系統中沒有可用的 GPU,則輸出為 cpu,代表程式會使用 CPU 進行運算。
1 | net.to(device) |
1 | net.to(device) |
當你執行 net.to(device) 時,PyTorch 會把模型中所有的參數(包含權重 weights 與偏差 biases)從預設的 CPU 記憶體移動到目標裝置上。如果系統有支援 CUDA 且 GPU 可用,模型就會被移到顯示卡中運行;若沒有 GPU,則會保留在 CPU 上。
1 | inputs, labels = data[0].to(device), data[1].to(device) |
1 | inputs, labels = data[0].to(device), data[1].to(device) |
data[0] 代表這一批的輸入圖片(影像張量),而 data[1] 則是對應的真實標籤(例如這張圖片是「貓」或「狗」)。這兩者最初都會存在 CPU 記憶體中,因為資料載入的預設裝置就是 CPU。
to(device) 是 PyTorch 用來把 Tensor 傳送到指定裝置的方法。如果前面設定的 device 是 'cuda:0',那這行指令會把 inputs 和 labels 都傳送到 GPU 記憶體中;如果沒有可用的 GPU,則會留在 CPU 上。這樣做可以確保模型(net)與資料位於相同的運算環境中,從而讓後續的運算(例如前向傳播、損失計算、反向傳播等)能夠正常執行。